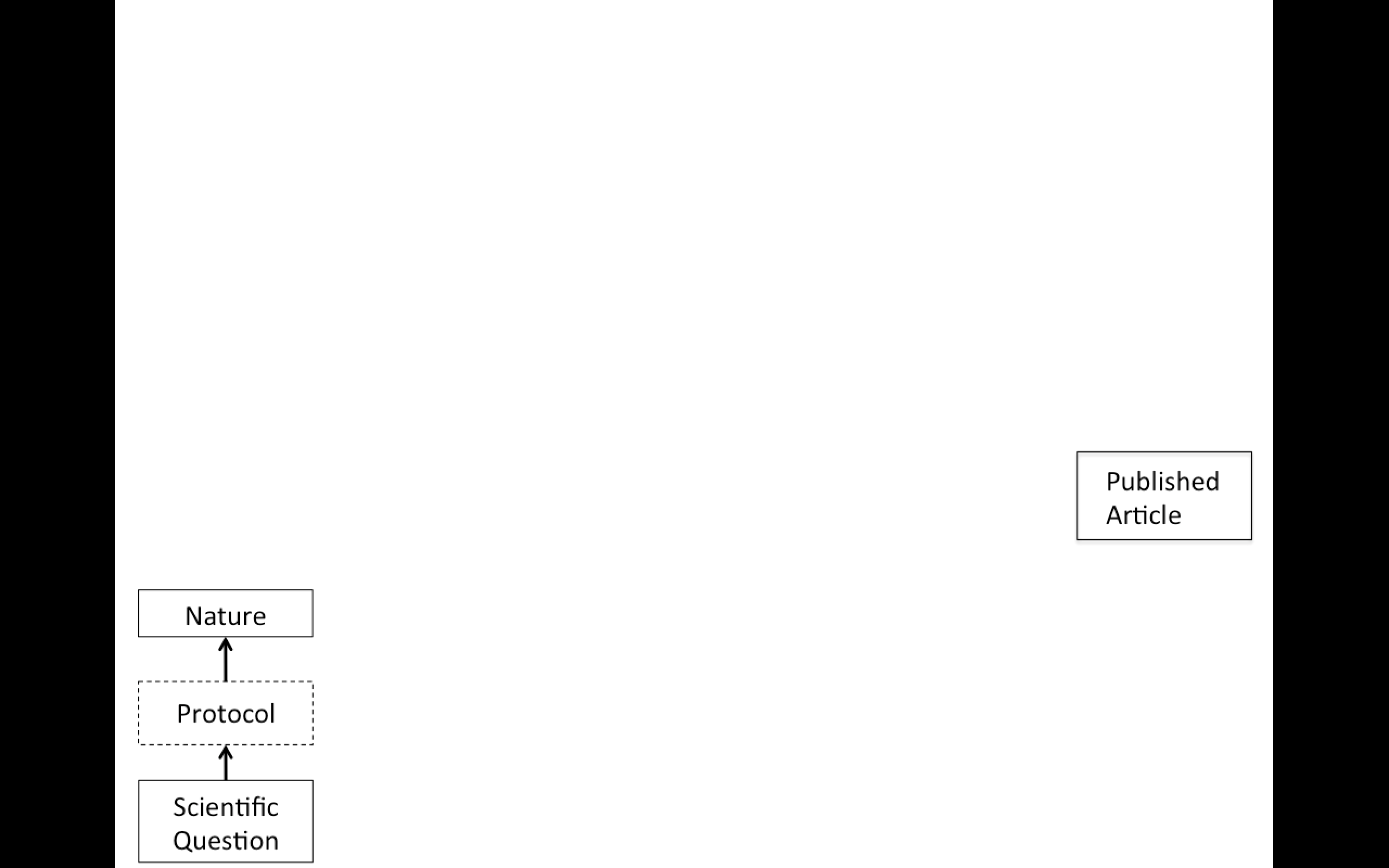
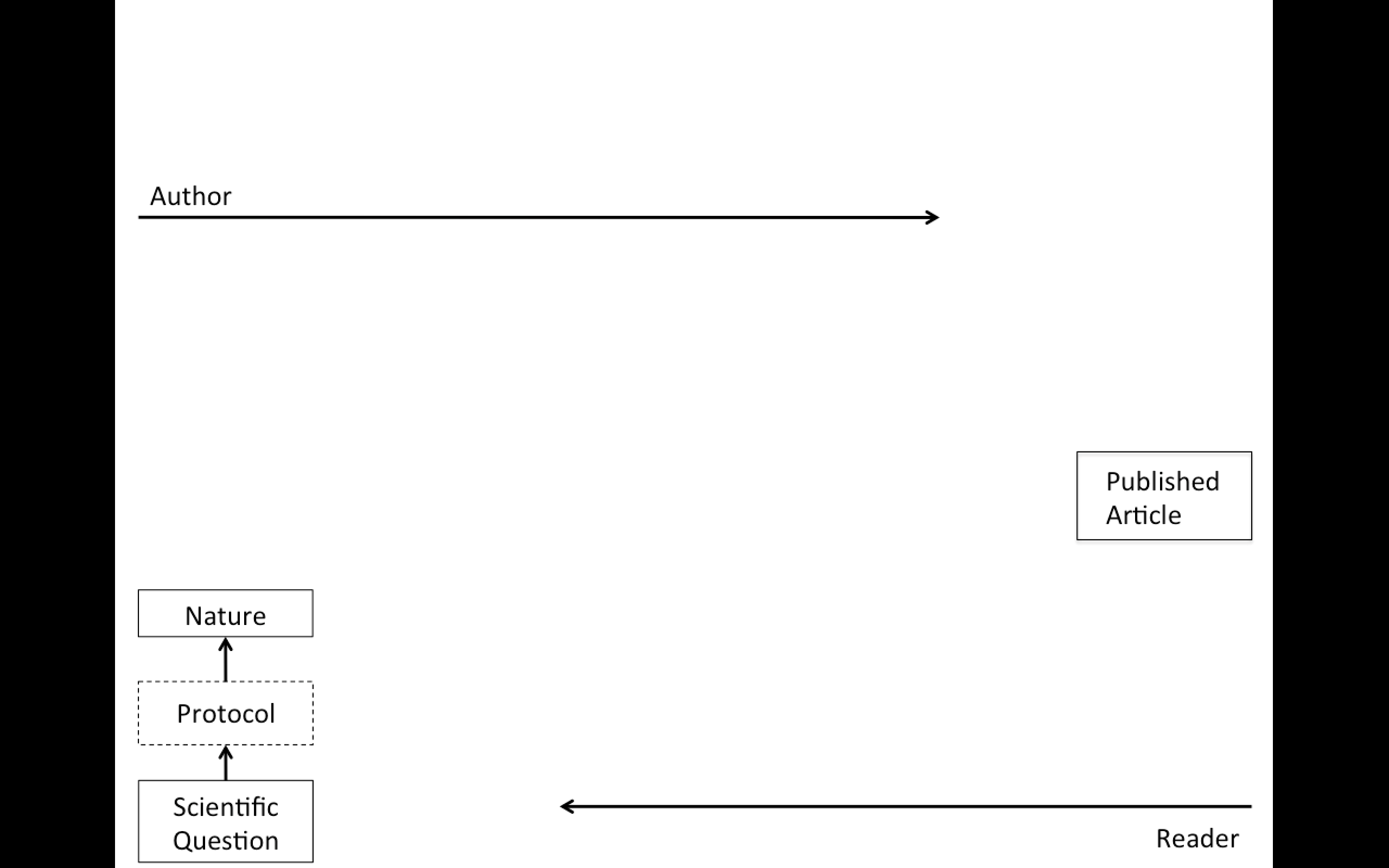
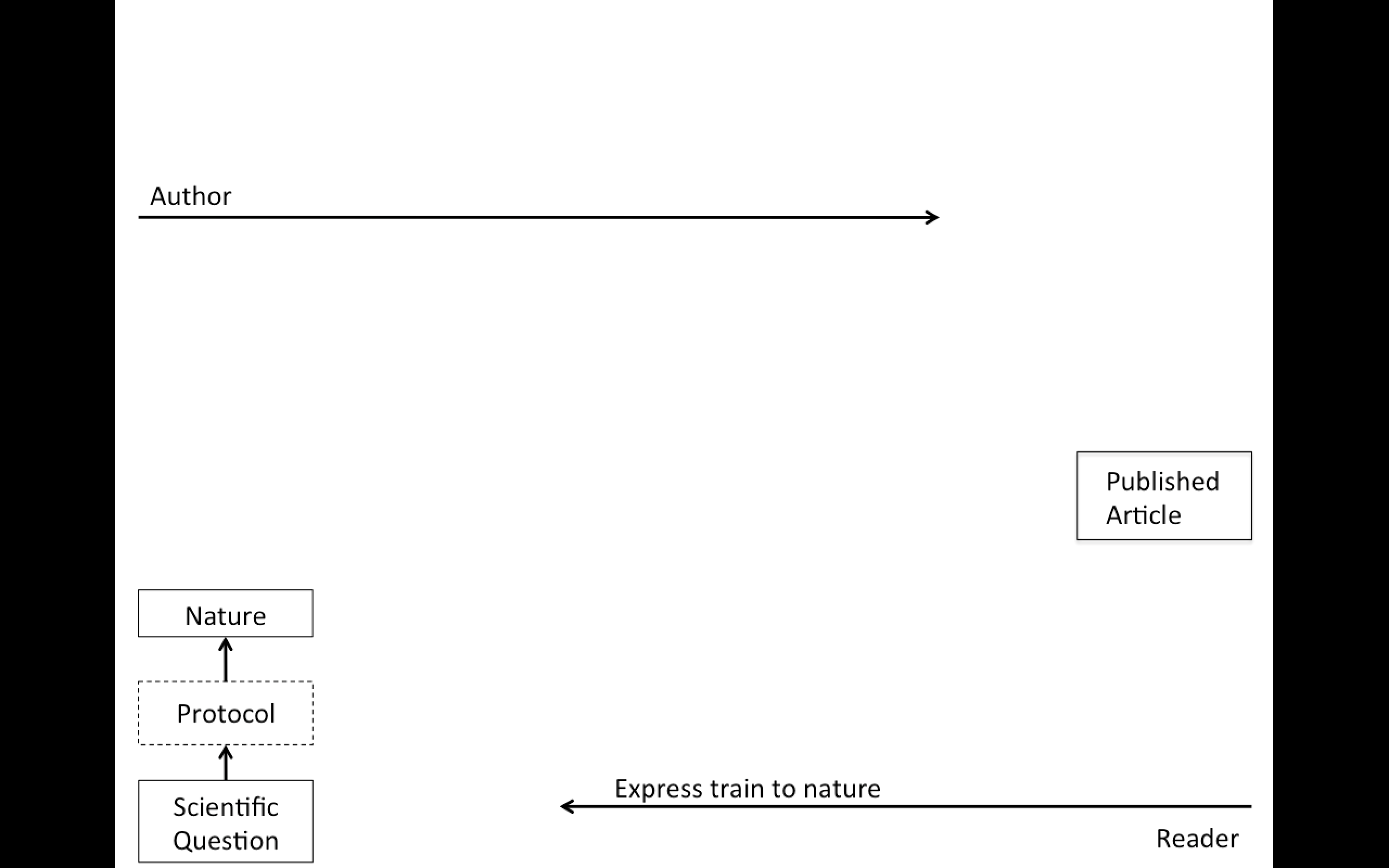
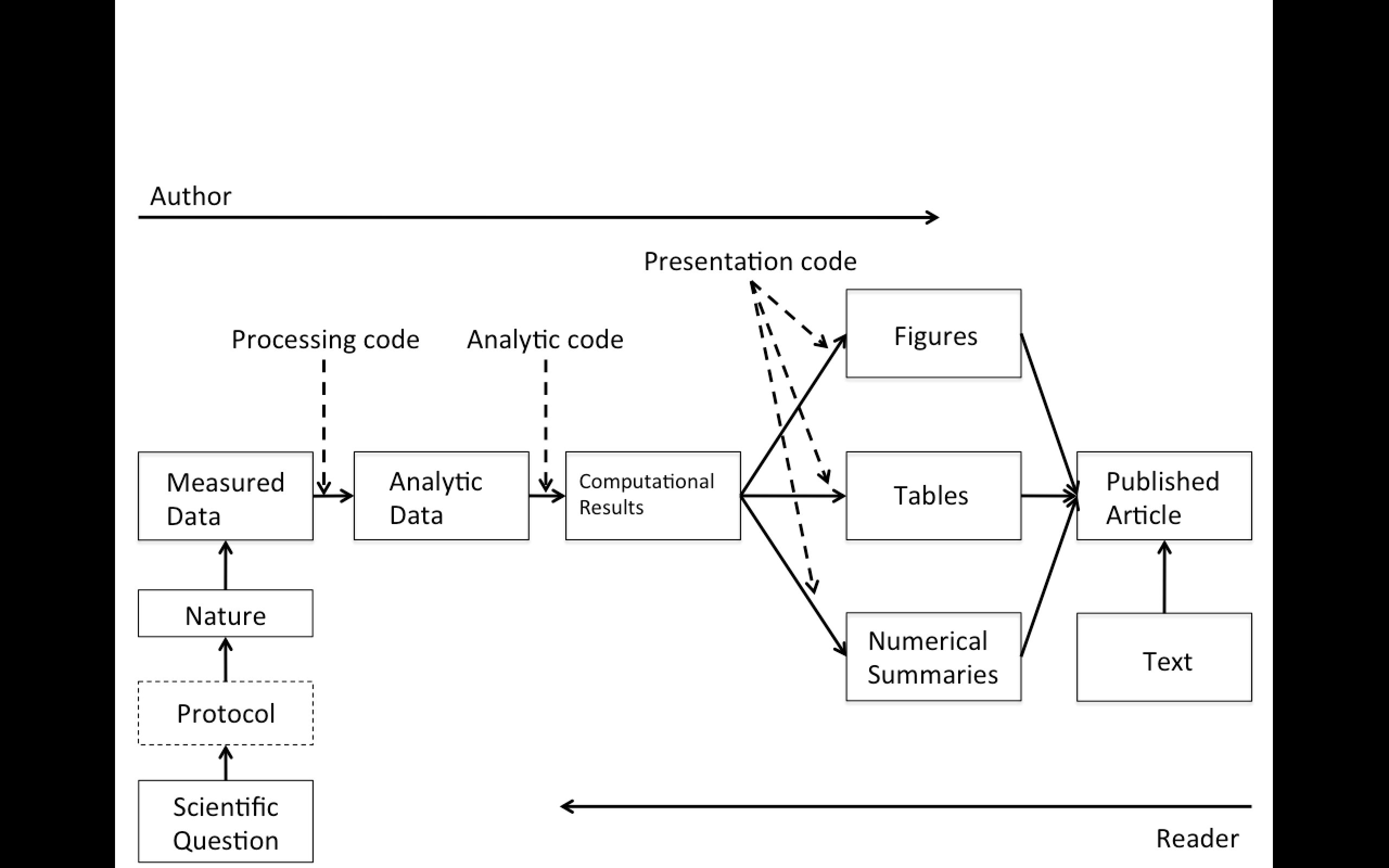
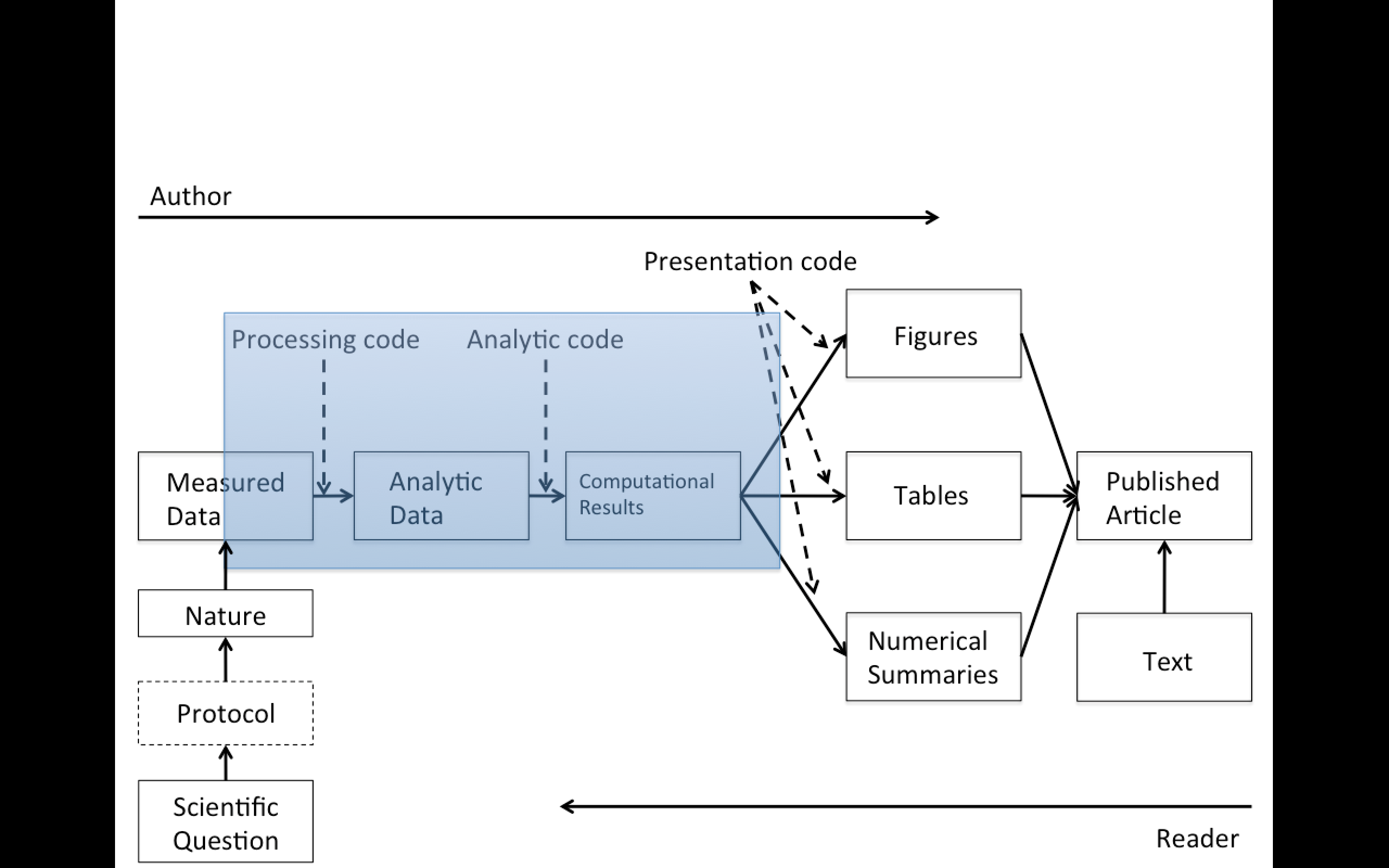
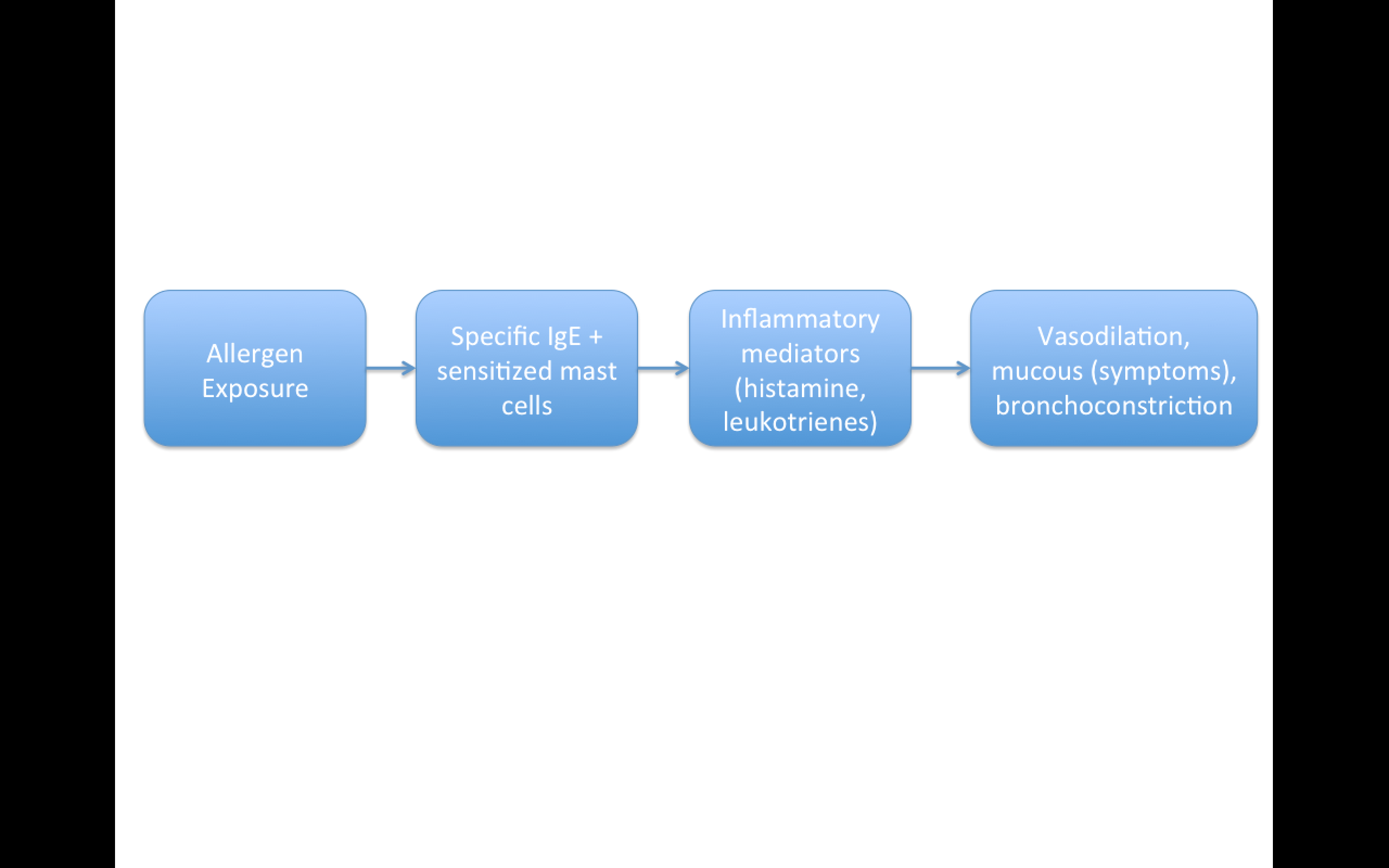
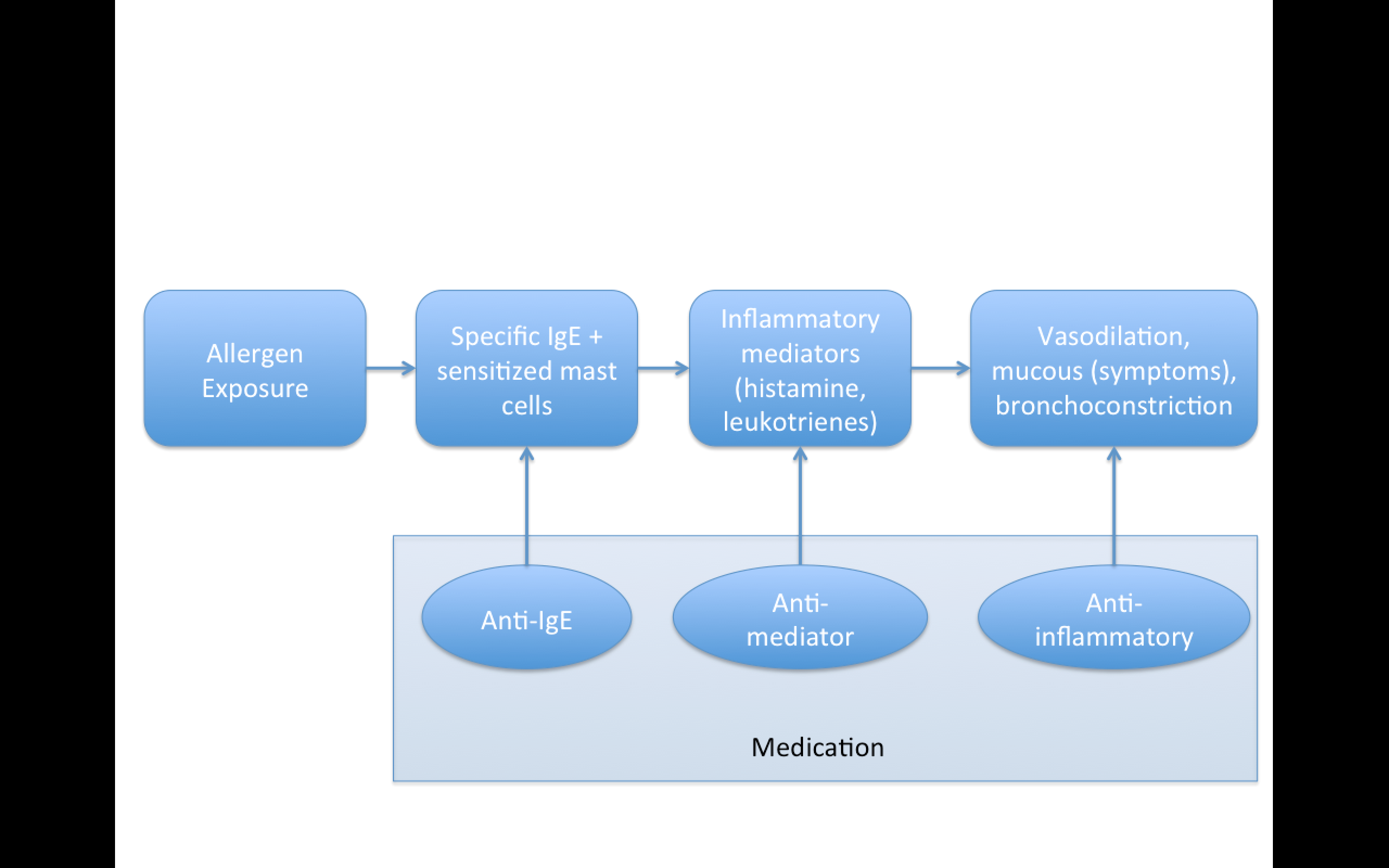
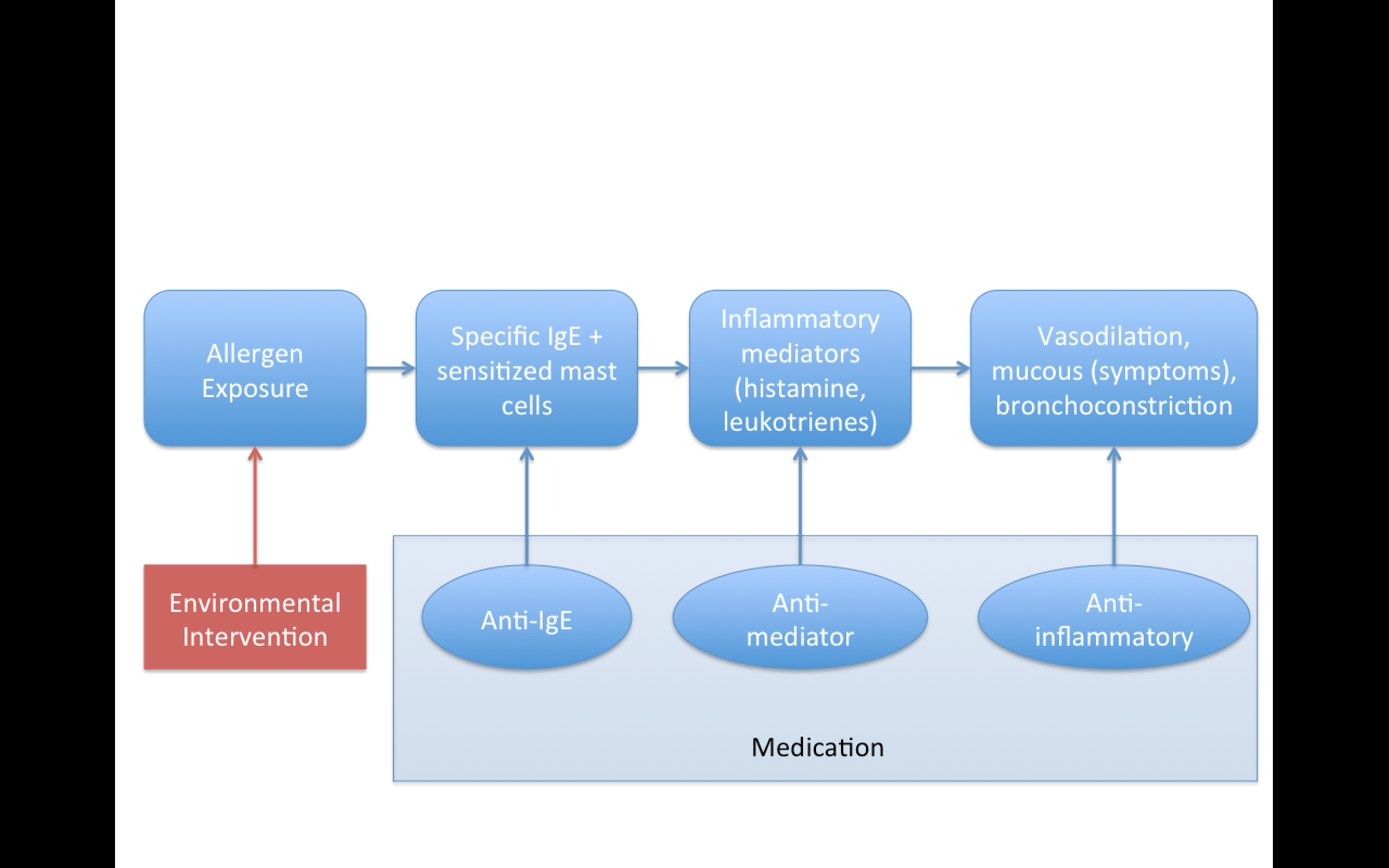
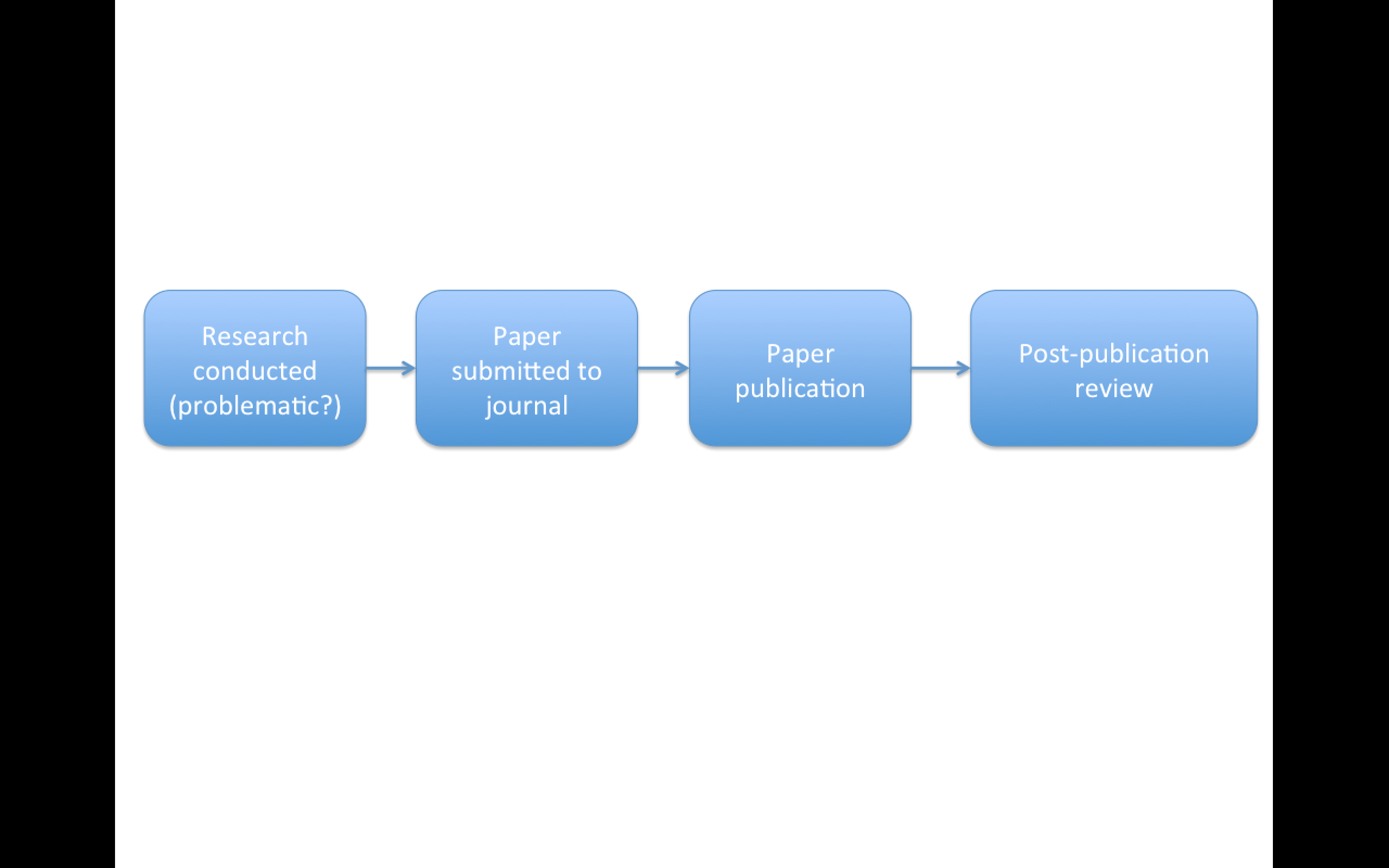
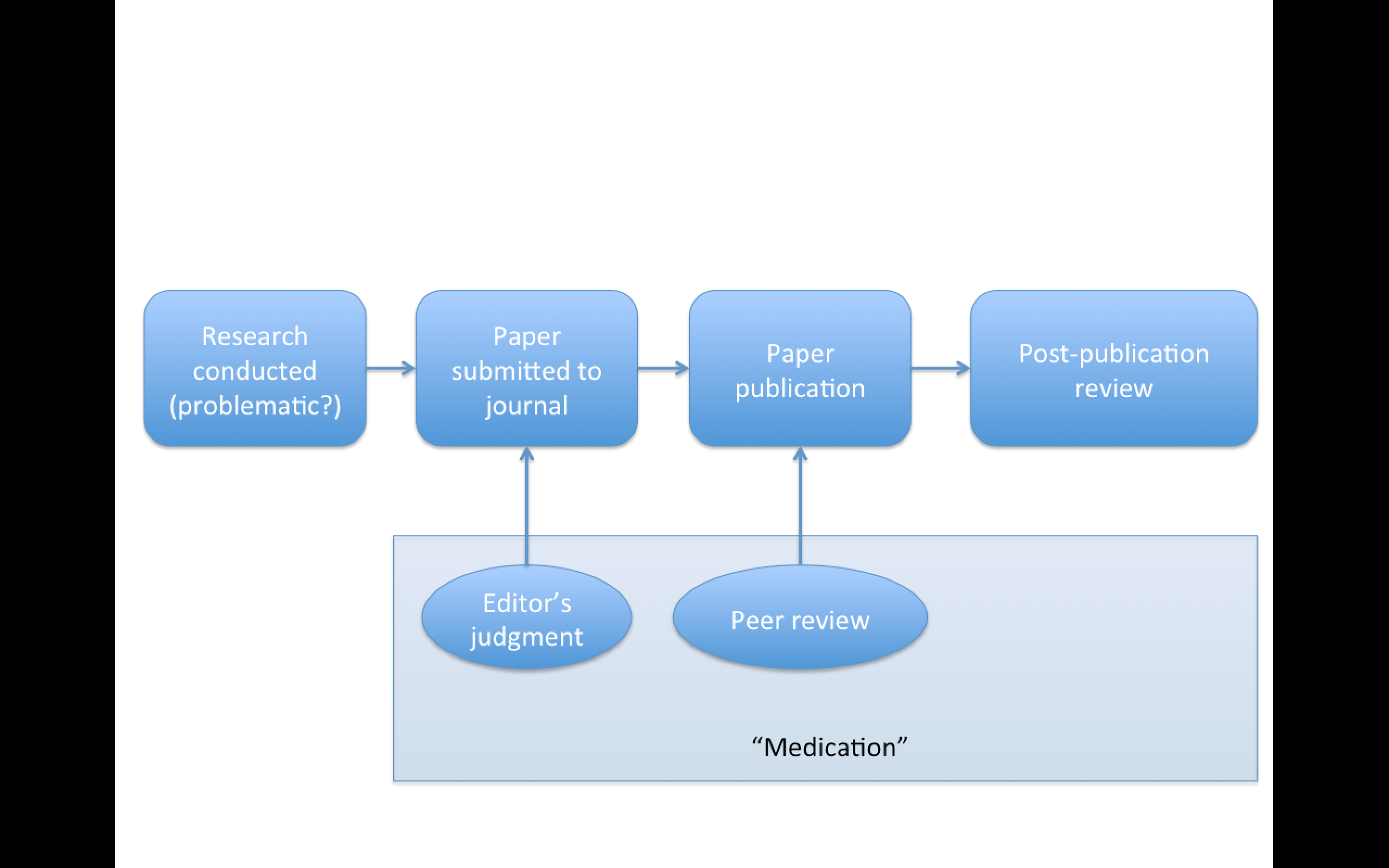
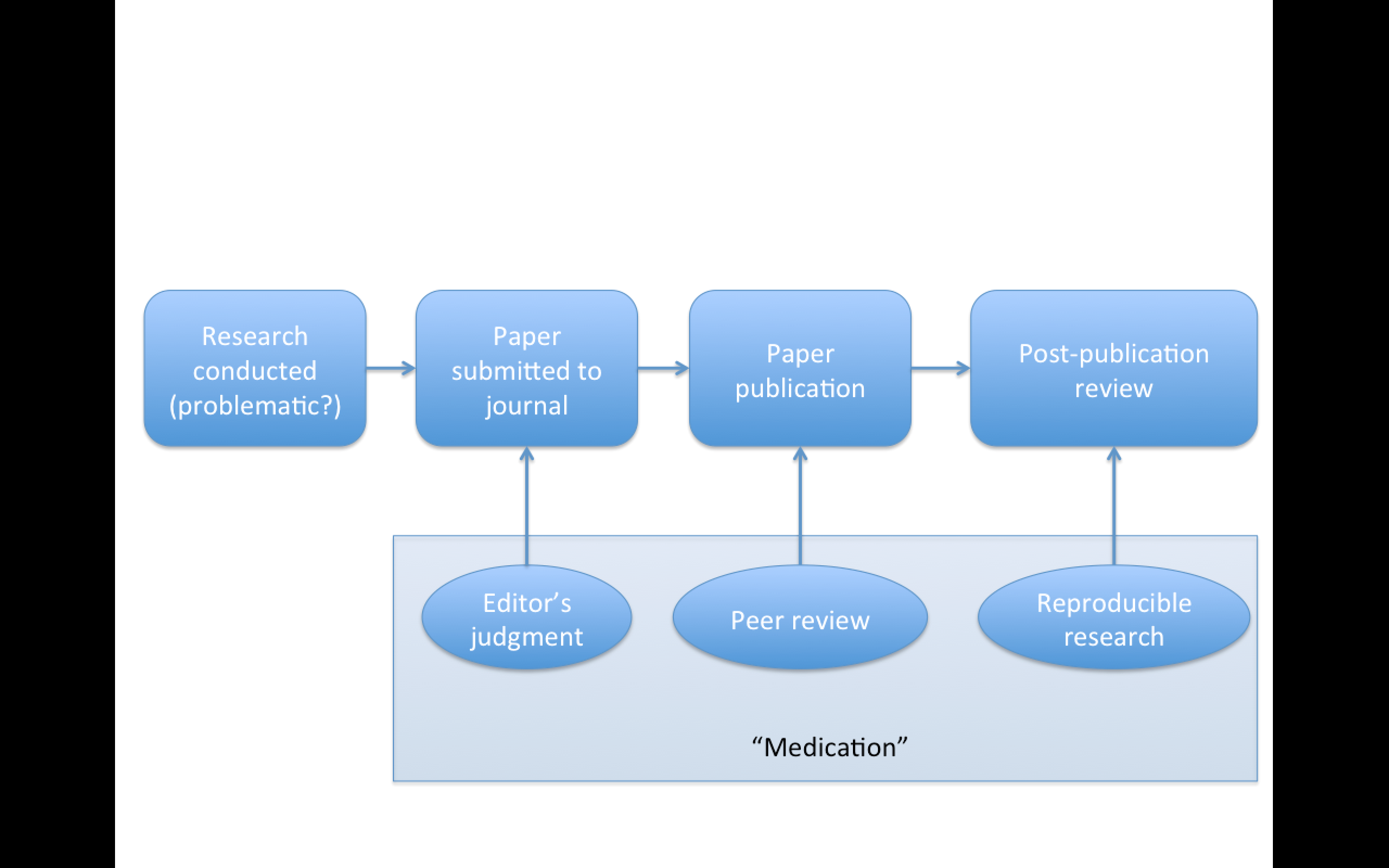
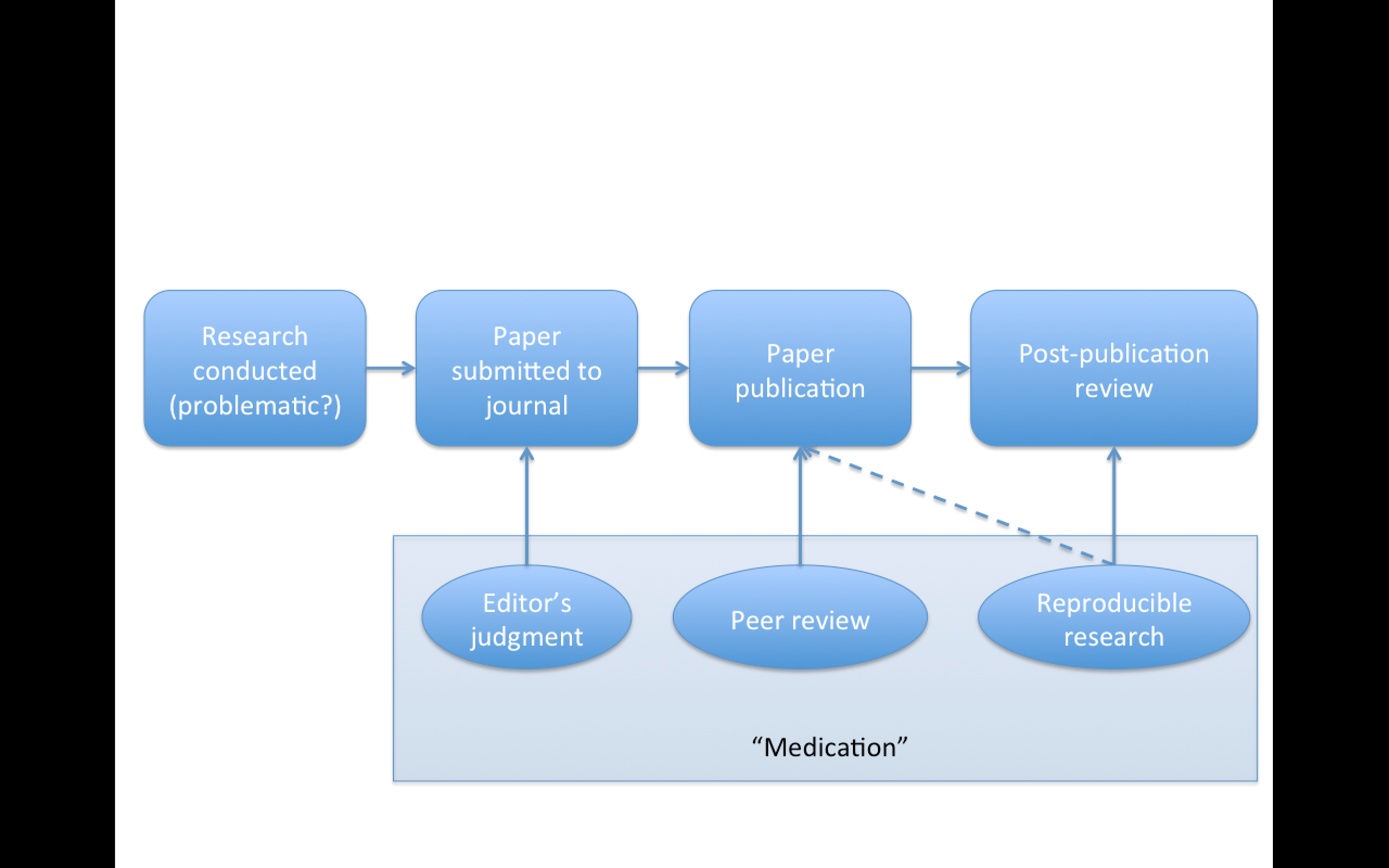
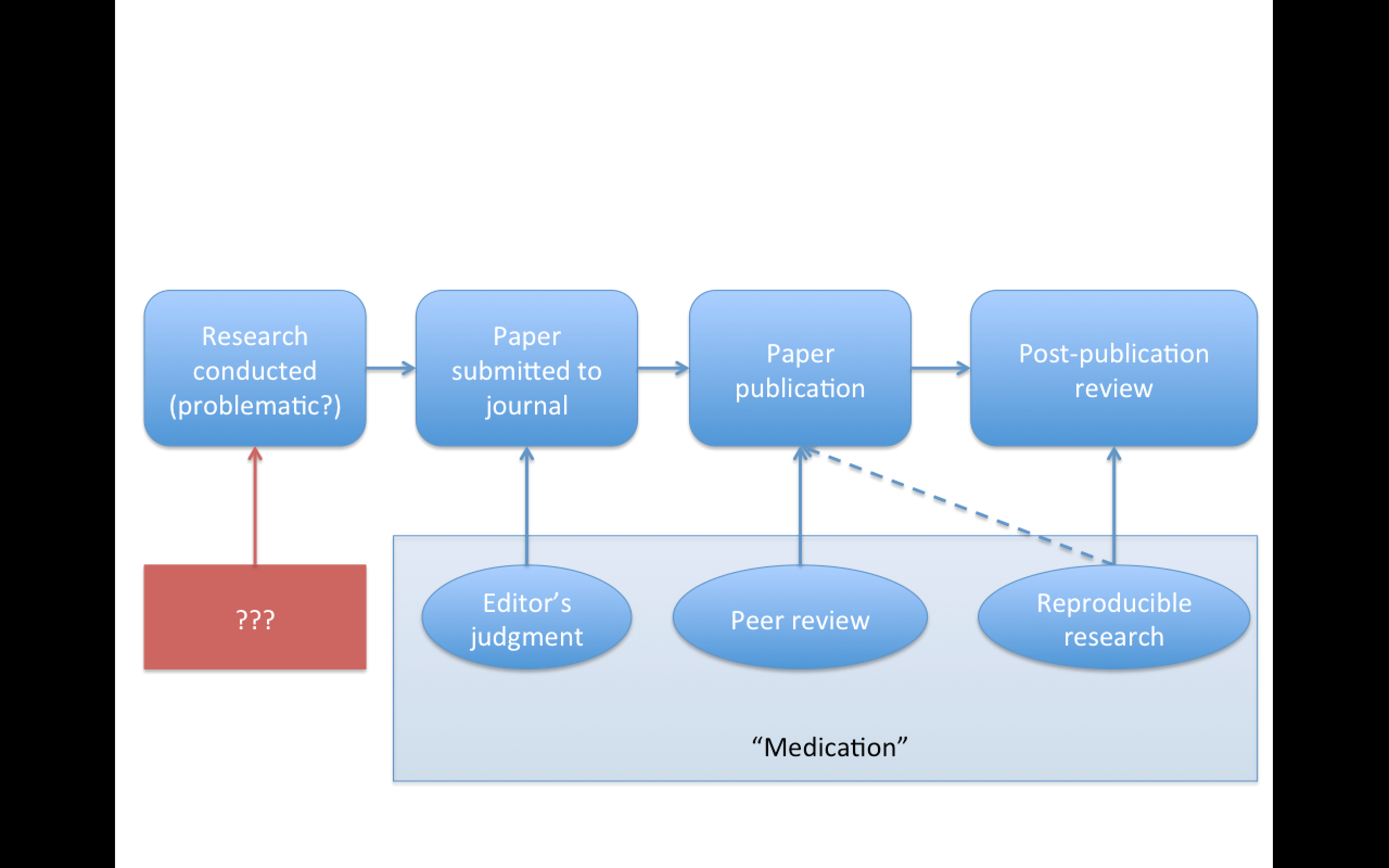
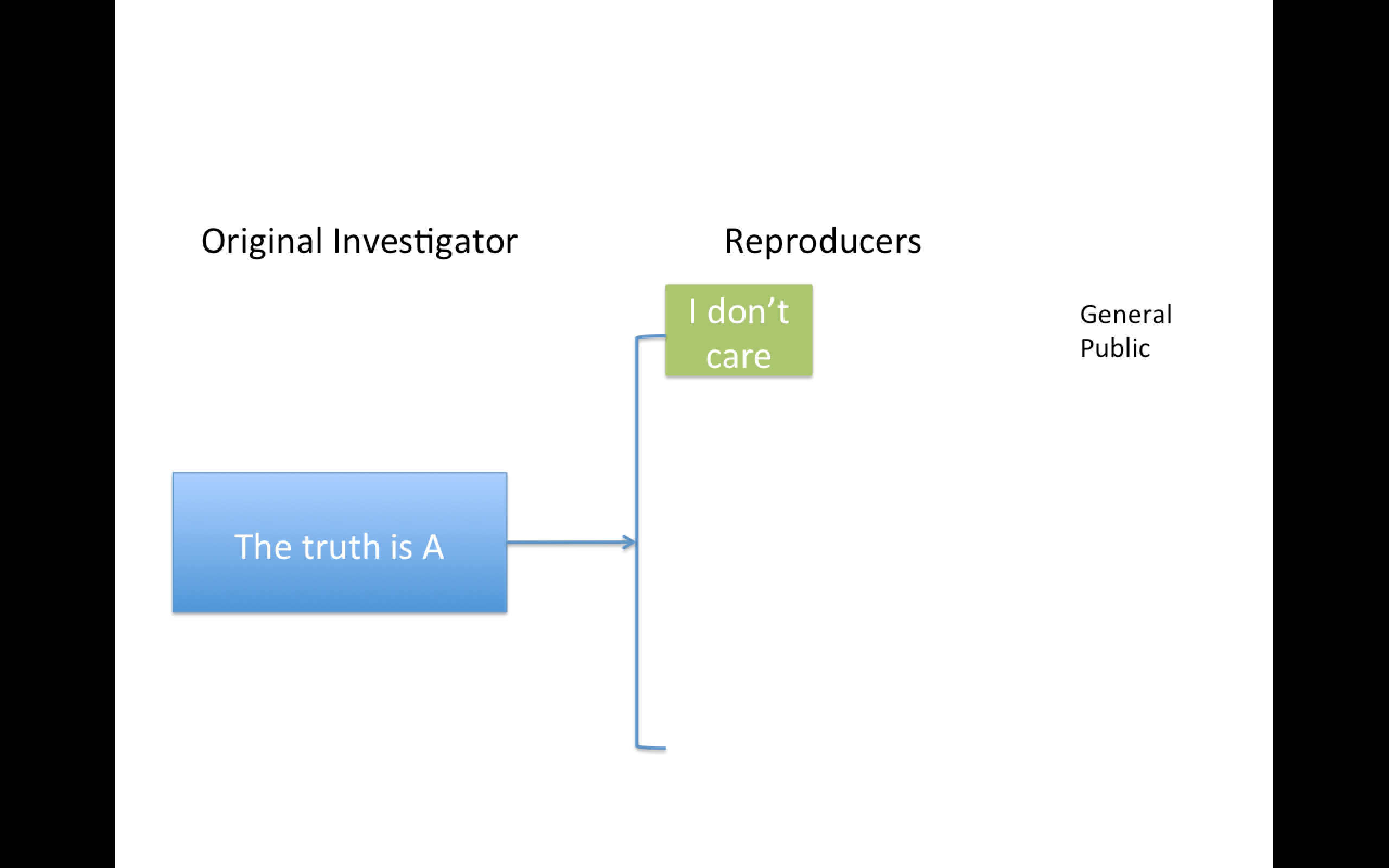
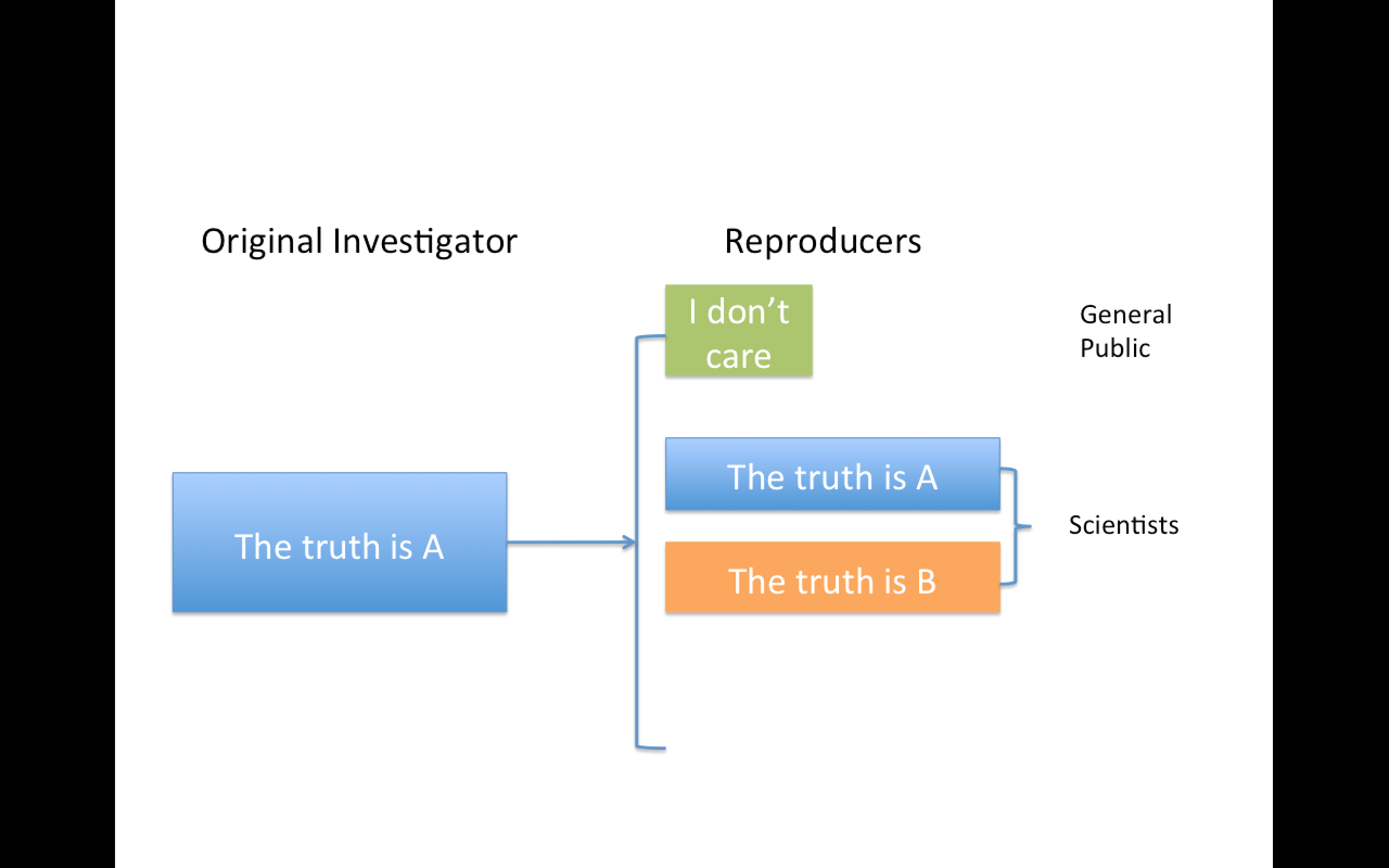
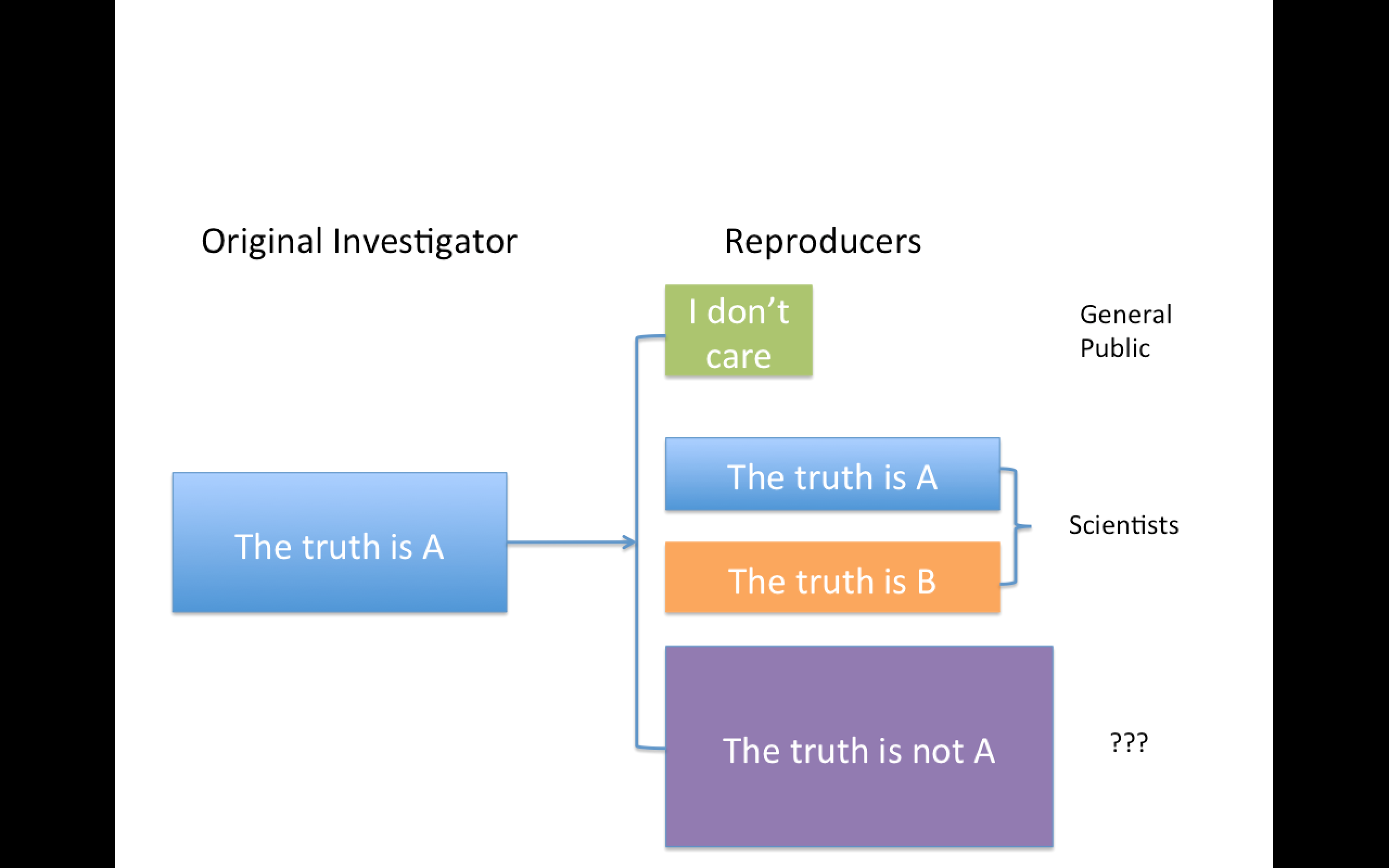
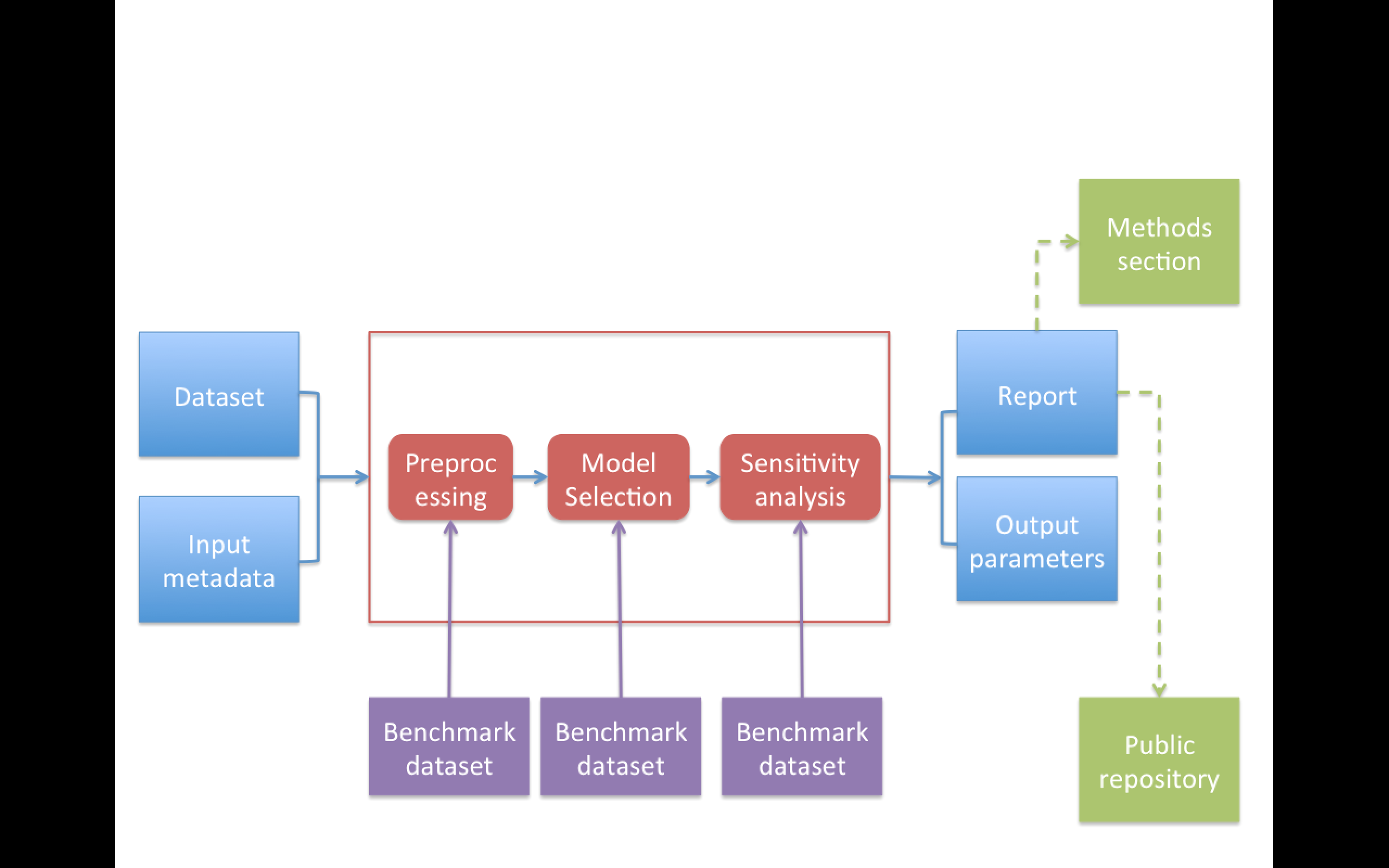
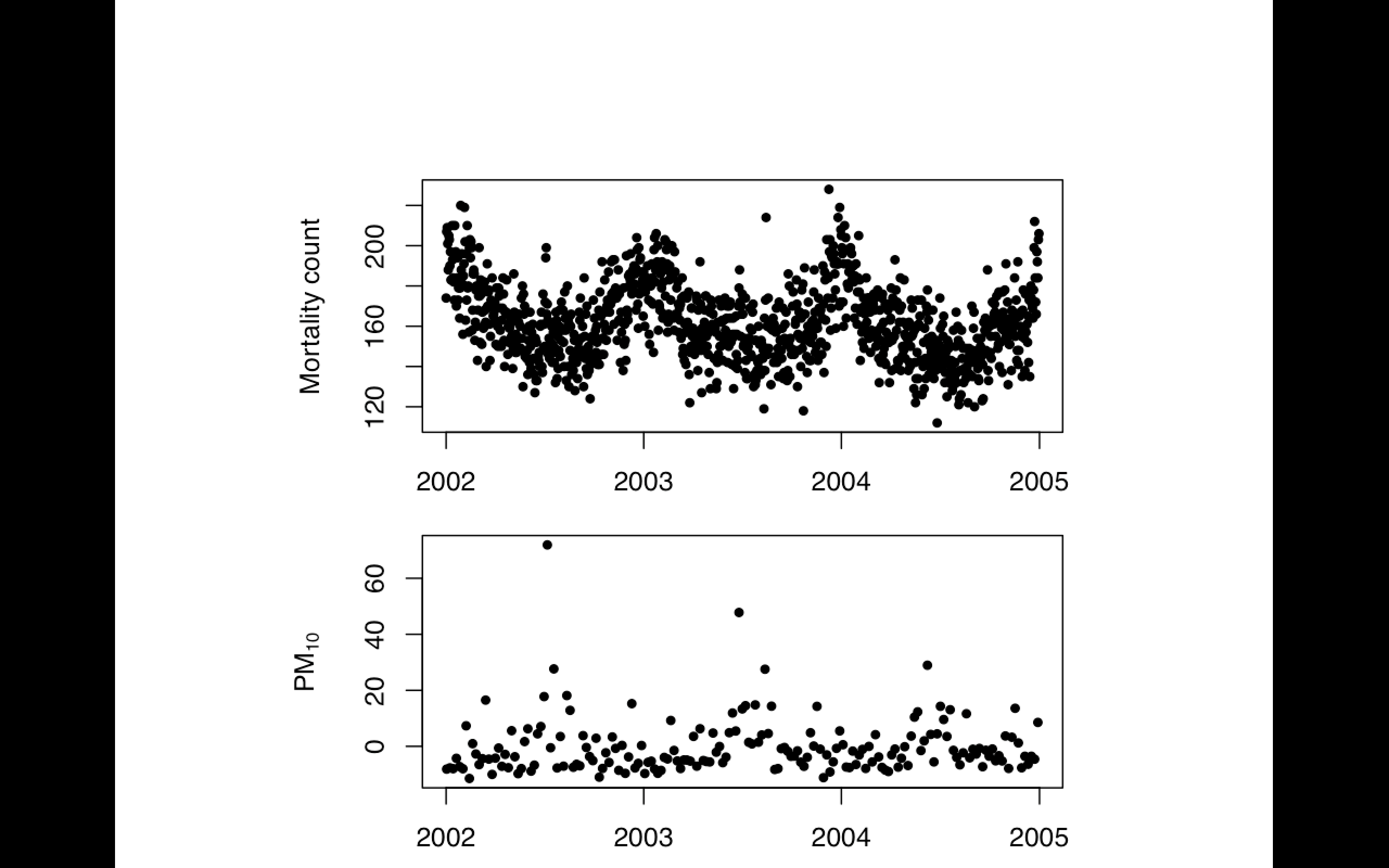
Replication
Focuses on the validity of the scientific claim
"Is this claim true?"
The ultimate standard for strengthening scientific evidence
New investigators, data, analytical methods, laboratories, instruments, etc.
Particularly important in studies that can impact broad policy or regulatory decisions